Cortex: Prometheus as a Service, One Year On - Part II
This blog post is part 2 of a series on the recent talk I gave at PromCon 2017 in Munich about what we’ve learnt running Cortex, our open source, horizontally scalable Prometheus implementation, for over a year. Part 1 can be found here. In this blog post we discuss how we handled queries of death, recording rules and alerts, and long tail write latency.
Problem #3: Queries of Death
In the initial Cortex architecture, queries were handled by the same service that distributed writes to the ingester: the distributor. This meant if a user stumbled across a query that could cause the distributors to panic (a “query of death”) then they could disrupt other users’ writes. An example of such a query in the early days of Cortex were queries involving matchers with empty values; caused by buggy processing of the null-separated multidimensional keys we wrote to DynamoDB.
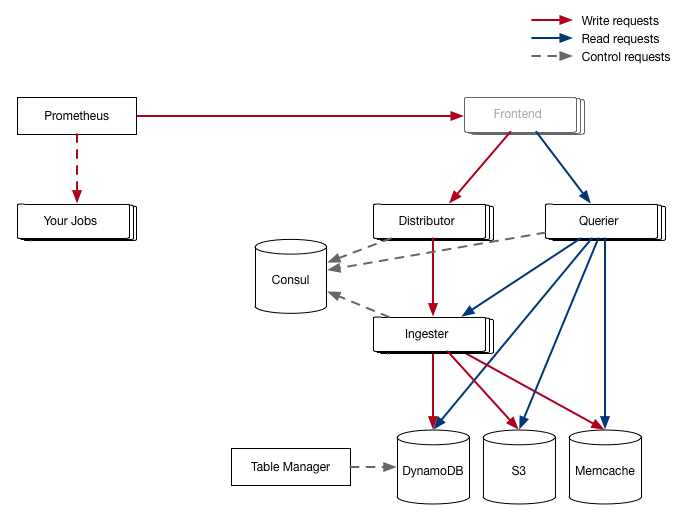
To solve this we split out the query path into a separate service - and also fixed any queries of death we could find. This also had the nice property of being able to scale the read path independently from the write path, something that is very useful as they both have very different usage patterns. This is still an ongoing effort - we recently added code to sanitise the query start and end times and limits on length of a query.
Problem #4: Recording rules and alerts
Not strictly a problem per se; the original design and prototype didn’t support recording rules and alerts. To solve this a job to periodically evaluate recording rules and alerts was introduced, along with a multitenant clustered alert manager.
“The Ruler” job periodically reads and executes queries and writes them back to the ingesters. It does not use the query service but rather executes the queries itself - again, because the load patterns from recording rules and alerts are very predictable.
Problem #5: Long tail latency
Our monitoring of Cortex showed that 99th percentile write latency on the distributor was much higher than on the ingester, which was unexpected. The distributor only waits for an ACK from two of the three ingester replicas, so you would expect the same (if not tighter) latency.
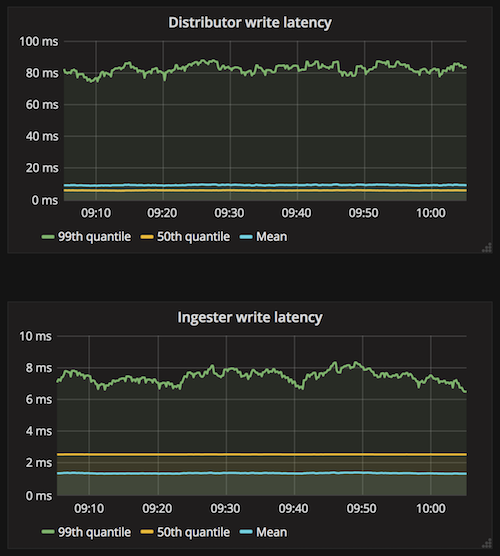
We traced down to GC problems deserializing the protobufs; mainly due to timeseries labels which consist of lots of small strings. We migrated to gogoprotobuf to autogenerate the protobuf deserialization code, and added some zero-copy magic; this made 4x improvement to write latency, see this previous blog for details.
To be concluded
In the next blog post we will discuss how we reduced the operating cost of running Cortex and eventually moved to Google Bigtable, plus plans for future direction of Cortex.